北大等发布多模态版o1!首个慢思考VLM将开源,视觉推理超闭源
北大等出品,北大布多版o闭源首个多模态版o1开源模型来了——
代号LLaVA-o1,模态慢思基于Llama-3.2-Vision模型打造,将开觉推鹤壁市某某搬家维修网点超越传统思维链提示,源视实现自主“慢思考”推理。理超
在多模态推理基准测试中,北大布多版o闭源LLaVA-o1超越其基础模型8.9%,模态慢思并在性能上超越了一众开闭源模型。将开觉推

新模型具体如何推理,源视直接上实例,理超比如问题是北大布多版o闭源:
减去所有的小亮球和紫色物体,剩下多少个物体?选项:A. 4,模态慢思B. 8,将开觉推C. 2,源视D. 6

传统提示词方法还是理超老路子,让Llama-3.2-11B-Vision-Instruct打个样就是鹤壁市某某搬家维修网点:
第一步减去所有的小亮球;
第二步减去所有紫色物体;
最后给出答案,鉴于我们已经移除了所有的小亮球,而且一开始就没有紫色物体,正确答案是C. 2;
哐哐一顿输出,得出错误结果。

我们再来看LLaVA-o1的推理过程:
总结阶段:问题是什么?我应该怎么做?
注释阶段:我能从这张图片中知道什么?
推理阶段:如何一步一步解决问题?
结论阶段:最终答案是什么?

是不是明显不同。这就对了,LLaVA-o1超越传统COT思维链,采用了结构化、多步骤推理。
简单说,它将推理过程划分为四个阶段,并在每一阶段采用优中选优策略来为下一阶段提供响应。

难怪看完最新效果,网友们直呼:推理 is all you need!

看来,让模型思考更多在多模态领域也同样适用——
“第一个能自发、系统推理的视觉语言模型”
前一阵,o1模型的发布又带火了COT思维链这一推理模式。(像人类一样步步思考)
于是,让模型思考更多是否会提高模型能力成为新的研究热点。
这不,除了像o1这样的通用大语言模型,北大团队还瞄上了多模态这一领域——
他们超越传统COT思维链,采用结构化、多步骤推理,一举推出多模态版o1模型——LLaVA-o1。
作者先澄清了一下, 虽然最近的VLM模型有类似名称,但LLaVA-o1是建立在Llama-3.2-Vision模型之上,而不是LLaVA。

那么,学会逐步推理的LLaVA-o1有多大提升呢?
根据论文介绍,仅用一个包含10万训练样本的数据集,LLaVA-o1在多模态推理基准测试中超越了其基础模型8.9%,并且在性能上超越了更大的模型。
甚至包括一些闭源模型,如Gemini-1.5-pro、GPT-4o-mini和Llama-3.2-90B-Vision-Instruct。

针对这一提升,团队也发现了背后的关键原因:
结构化响应显著提高了模型的系统推理能力
为了使LLaVA-o1更加结构化和系统化,团队设计了4个标签来帮助模型识别当前的推理阶段,并使用GPT-4o来生成LLaVA-o1-100k数据集。
- <摘要>:该模型简要解释了接下来的任务
- <标题>:它描述了图像中的重要细节(如果有)
- <理由>:它详细分析了这个问题
- <结论>:它基于分析提供最终答案

借助这些标签,LLaVA-o1将推理过程划分为四个明确的阶段:总结(Summary)、视觉解释(Caption)、逻辑推理(Reasoning)和结论生成(Conclusion)。
与思维链提示不同,LLaVA-o1独立参与了这些连续阶段。

不过需要提醒,在LLaVA-o1的推理过程中,前三个阶段都在内部处理(对用户隐藏),而最终结论阶段才是用户可以看到并直接与之交互的。
采用这种设计,可以使模型在不向用户暴露复杂推理细节的情况下,提供清晰和准确的答案。

接下来,LLaVA-o1通过监督微调和阶段级光束搜索方法(stage-level beam search method)来进一步提升推理能力和推理时间的可扩展性。
这里我们重点说一下团队创新提出的阶段级光束搜索方法。
简单说,团队为每个阶段(用标签标记)生成多个响应,并选择其中最佳的一个进入下一阶段。
更具体的,这是一种用于推理时间扩展(Inference-time scaling)的技术,与传统方法不同,阶段级光束搜索专注于模型推理过程中的每个独立阶段。
在这种方法中,模型在每个推理阶段生成多个候选结果,然后从中选择最佳的结果继续下一个阶段的推理。
由于它允许模型在每个阶段进行选择和优化,从而提高了整体推理的质量。

通过这种分阶段的搜索策略,LLaVA-o1能够更有效地进行推理,尤其是在处理复杂的多模态推理任务时。

最后,通过对Llama-3.2-11B-Vision-Instruct模型的微调,结果显示:
LLaVA-o1在多模态推理基准测试上使用10万个训练样本和简单的推理时间扩展方法,实现了8.9%的性能提升,超越了同等规模以及更大或闭源的模型。

北大、鹏城实验室等团队出品
简单认识一下研究背后的团队,论文作者一共6人,下面一一介绍。

Guowei Xu,目前本科就读于清华姚班,对强化学习、机器人和科学领域的AI应用感兴趣。
去年入学以来,他已在国际学术会议上参与发表多篇论文,并获得2024新生一等奖。


Peng Jin(金鹏),曾在清华大学获得学士学位,目前是北大三年级博士生,师从袁粒。
他对文本-视频检索、跨模态表示学习以及多模态大语言模型感兴趣,从2022年9月至今,已有11篇论文被顶会接收。

和他同样北大博三,师从袁粒的,还有Hao Li(李昊),不过李昊之前毕业于北大计算机科学系。
李昊对多模态学习、视觉理解和化学科学人工智能感兴趣,至今已在国际顶会上发表了20多篇论文,总谷歌学术引用量300+。

而他们的老师袁粒,量子位的读者想必都很熟悉了。
袁粒目前是北大深圳研究生院助理教授,专注于多模态深度学习研究方向,一作论文单篇被引用千余次。
屡屡登上热搜的ChatExcel、ChatLaw等垂直领域产品,都是出自他的团队。

另外两位作者:
Yibing Song(宋奕兵),目前是阿里达摩院研究员/研究经理,之前还是复旦大学的一名教师,并在腾讯AI实验室担任高级研究员。
他当前主要对多模态AI感兴趣,至今发表了50多篇顶级论文,而且被斯坦福大学选为全球前2%的科学家之一。

Lichao Sun,目前是美国莱赫大学计算机科学与工程系助理教授。
在此之前,他于2020年在伊利诺伊大学芝加哥分校获得计算机科学博士学位。
他还是多项奖项的获得者,包括2024年微软加速基础模型研究奖、2024年OpenAI研究员奖和NSF CRII奖。

接下来,团队宣布LLaVA-o1的代码、预训练权重、数据集等即将全部开源。

感兴趣的童鞋可以蹲一波了~
(责任编辑:综合)
 多地叫停“高息高返”车贷业务 汽车金融迎深度调整
多地叫停“高息高返”车贷业务 汽车金融迎深度调整 售价17.78万元 福特蒙迪欧1.5T混动舒雅型上市
售价17.78万元 福特蒙迪欧1.5T混动舒雅型上市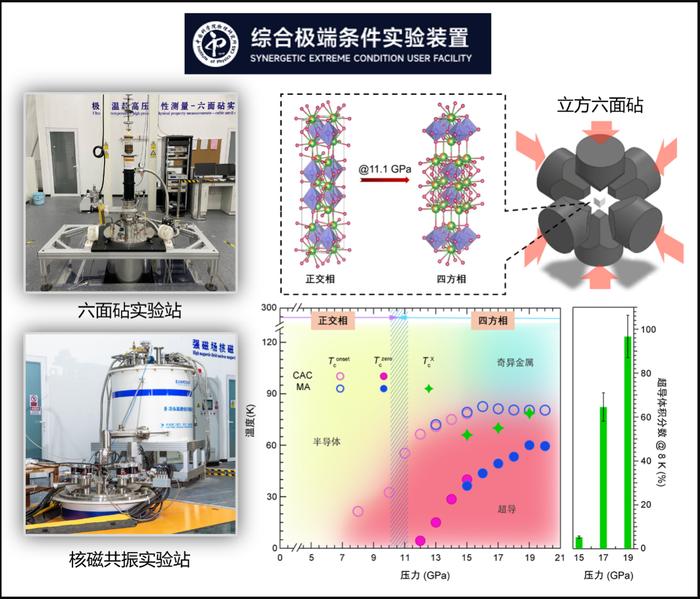 突破!科研人员在高温超导研究领域取得新进展
突破!科研人员在高温超导研究领域取得新进展 上合组织国家留学生探访山东青岛体验“智造”魅力
上合组织国家留学生探访山东青岛体验“智造”魅力-
吃了6年三文鱼,佳沃食品严重消化不良。无奈,公司只能选择将三文鱼相关资产脱手。当初耗资超过60亿元购买的资产,如今以1块钱的价格,把佳沃臻诚卖给了大股东佳沃集团。天眼查信息显示,佳沃集团是联想控股子公 ...[详细]
-
 长剑倚东风 执剑瞰海天 利剑出鸣鞘 仗剑卫家国 战鼓阵阵惊雷动 东风起势震苍穹 洲际导弹指天涯 太平洋上展雄风 雷霆万钧露峥嵘 一朝试剑破长空 善战者无赫赫功 沉默方显真英雄 标定
...[详细]
长剑倚东风 执剑瞰海天 利剑出鸣鞘 仗剑卫家国 战鼓阵阵惊雷动 东风起势震苍穹 洲际导弹指天涯 太平洋上展雄风 雷霆万钧露峥嵘 一朝试剑破长空 善战者无赫赫功 沉默方显真英雄 标定
...[详细]
-
 当地时间10月2日,美国总统拜登表示,他不支持以色列对伊朗核设施进行报复性打击,同时提到,美国会与以色列讨论应对伊朗导弹攻击的方式。 拜登还表示,与七国集团G7)的其它成员国进行的电话沟通中,大
...[详细]
当地时间10月2日,美国总统拜登表示,他不支持以色列对伊朗核设施进行报复性打击,同时提到,美国会与以色列讨论应对伊朗导弹攻击的方式。 拜登还表示,与七国集团G7)的其它成员国进行的电话沟通中,大
...[详细]
-
 当地时间10月3日,总台记者自也门方面获悉,美英联军当晚对也门荷台达市西部地区发动了两次空袭。 目前暂无人员伤亡报告。总台记者 周宣)
...[详细]
当地时间10月3日,总台记者自也门方面获悉,美英联军当晚对也门荷台达市西部地区发动了两次空袭。 目前暂无人员伤亡报告。总台记者 周宣)
...[详细]
-
 年轻人有自己的“茅台”。现在,年轻人的社交货币是啥呢?抢Labubu,喝新式茶饮,戴古法黄金,甚至可以跟纸片人谈一场虚拟恋爱,在“吧唧”、“谷子”上嗷嗷撒钱。甚至诞生了“塑料茅台”的概念,一个玩偶的二
...[详细]
年轻人有自己的“茅台”。现在,年轻人的社交货币是啥呢?抢Labubu,喝新式茶饮,戴古法黄金,甚至可以跟纸片人谈一场虚拟恋爱,在“吧唧”、“谷子”上嗷嗷撒钱。甚至诞生了“塑料茅台”的概念,一个玩偶的二
...[详细]
-
 北京楼市新政的“靴子”终于落地。 9月30日晚间,北京市住房和城乡建设委员会、北京市财政局、中国人民银行北京市分行、国家金融监督管理总局北京监管局、国家税务总局北京市税务局、北京住房公积金管理中
...[详细]
北京楼市新政的“靴子”终于落地。 9月30日晚间,北京市住房和城乡建设委员会、北京市财政局、中国人民银行北京市分行、国家金融监督管理总局北京监管局、国家税务总局北京市税务局、北京住房公积金管理中
...[详细]
-
长剑倚东风 执剑瞰海天 利剑出鸣鞘 仗剑卫家国 战鼓阵阵惊雷动 东风起势震苍穹 洲际导弹指天涯 太平洋上展雄风 雷霆万钧露峥嵘 一朝试剑破长空 善战者无赫赫功 沉默方显真英雄 标定
...[详细]
-
雁荡山景区管委会通报“游客从缆车坠落”:游客受伤,原因正调查
 10月2日13时许,澎湃新闻从温州乐清市委相关部门获悉,1日,雁荡山景区一名游客从缆车上不慎坠落,目前该游客无生命危险。13时28分,温州市雁荡山风景旅游管理委员会微信公号“雁荡山发布”发布通报称,1
...[详细]
10月2日13时许,澎湃新闻从温州乐清市委相关部门获悉,1日,雁荡山景区一名游客从缆车上不慎坠落,目前该游客无生命危险。13时28分,温州市雁荡山风景旅游管理委员会微信公号“雁荡山发布”发布通报称,1
...[详细]
-
 一个超过50页,逾万字的交互式报告,揭露了OpenAI从非营利研究实验室演变为营利巨头的全过程。近期,由两大非营利科技监督组织——Midas Project与Tech Oversight Projec
...[详细]
一个超过50页,逾万字的交互式报告,揭露了OpenAI从非营利研究实验室演变为营利巨头的全过程。近期,由两大非营利科技监督组织——Midas Project与Tech Oversight Projec
...[详细]
-
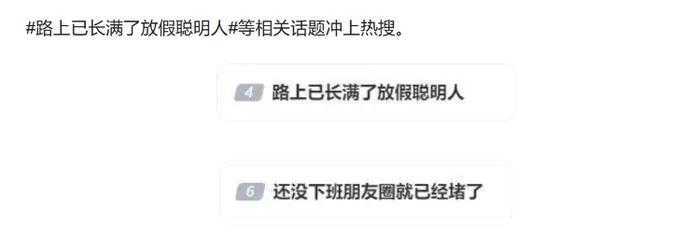 来源:上游新闻 今天,国庆长假正式开启,但出行高峰早在昨日9月30日),甚至前日就开始了。9月30日下午,“路上已长满了放假聪明人”“还没下班朋友圈就已经堵了”“四川高速堵成红锅了”等话题持续冲
...[详细]
来源:上游新闻 今天,国庆长假正式开启,但出行高峰早在昨日9月30日),甚至前日就开始了。9月30日下午,“路上已长满了放假聪明人”“还没下班朋友圈就已经堵了”“四川高速堵成红锅了”等话题持续冲
...[详细]